
Knowledge Has a Shelf Life. Most Teams Don’t Check It.
In chemistry, a half-life is how long it takes for half of a substance to decay. The concept transfers cleanly to knowledge: how long before half the specific claims in a piece of guidance are superseded, contradicted, or rendered incomplete by newer work?
Academic research on neural network methods has an estimated half-life of 18–24 months on specific techniques. Developer platform guidance — the blog posts, tutorials, and setup walkthroughs that teams actually use to onboard — decays faster. For an actively-shipped tool, the half-life is closer to 6–12 months. And both intervals are compressing.
This isn’t a theoretical problem. Teams adopt AI tooling from guides they find through search. Those guides were accurate when written. Nobody checks the expiration date before following them. Your team is probably following one right now.
This report scores a specific case to make the decay visible.
The Case Study: One Guide, Seven Months Later
Last August, a developer named Robert Marshall published a detailed guide: Turning Claude Code into a Development Powerhouse. It was thoughtful, firsthand, and credible. It described a setup that cut his time on complex features by 60–70%. It circulated widely in developer communities and became a reference point for teams adopting Claude Code.
By March 2026, that same guide scores 3.8 out of 10 against current platform practice.
Not because it was wrong. Because the platform shipped faster than any individual blogger can follow.
The pattern isn’t unique to this article. Even canonical academic research on LLM hallucination — carefully written and well-cited — scores 5.6/10 against current practice after less than two years. Developer tooling advice, which sits closer to the implementation surface, decays even faster.
What the Decay Looks Like, Measured
Five dimensions, each scored on a scale of 0–10:
| Dimension | Score | What It Captures |
|---|---|---|
| Factual Accuracy | 6 | Are the specific claims still correct? |
| Relevance | 7 | Does the problem framing still apply? |
| Staleness | 3 | How much of what it recommends has been superseded? |
| Completeness | 2 | Does it cover what the platform can actually do today? |
| Workflow Coverage | 3 | Does it reflect how practitioners configure Claude Code in 2026? |
| Composite | 3.8 |
Audited against official Claude Code documentation · Reference date March 28, 2026
The gap between a 7 on relevance and a 2 on completeness is where the epistemology gets interesting. The problem Marshall identified — that without persistent context, Claude produces generic outputs that ignore your project’s conventions — is still the right problem. The solutions he recommends address roughly 5% of how the platform answers that problem today.
This is characteristic of how knowledge decays in fast-moving platforms: the diagnosis stays valid long after the prescription expires. Teams following the article get the problem right and the implementation wrong, which is arguably more dangerous than getting both wrong — because the correct diagnosis creates false confidence that the implementation is also current.
Three Categories of Decay
Not all knowledge decays at the same rate. The audit reveals three distinct categories, each with different shelf lives and different verification strategies.
1. Problem Framing — Durable (Review Annually)
Marshall’s core insight — that LLM output quality is a function of the context it receives, and that persistent project context produces better results than cold-start sessions — is as true in March 2026 as it was in August 2025. His recommendation to plan before executing, to break requirements into smaller chunks, and to inject project-specific context at query time: all durable.
Problem framing decays slowly because it tracks to the underlying architecture of the technology, not the feature surface. When the model architecture changes (a new context window size, a new memory mechanism), the framing may shift. Until then, it holds.
Verification cost: low. Read the official overview once a quarter. If the fundamental model interaction pattern hasn’t changed, the framing is still valid.
2. Feature Surface — Perishable (Validate Before Every Onboarding)
This is where the guide’s score collapses.
Marshall’s setup centered on four add-on tools (called MCP integrations — connectors that give Claude access to external information in real time) and a custom startup command that loaded a project context file before each session.
In the seven months since publication, the platform shipped an entire automation layer the article doesn’t know about:
Hooks — automated triggers that run at specific points in Claude’s workflow — before it uses a tool, after it completes a task, at the start and end of a session. They can enforce rules, block certain actions, verify outputs, and maintain context automatically. The difference is structural: Marshall’s /go command is a checklist you run manually before every flight. Hooks are the autopilot systems that enforce safety conditions throughout.
Native memory — Claude Code now automatically accumulates project-specific knowledge: build patterns, debugging history, architectural preferences, repeated corrections. The problem the article solved with a manually-maintained context file has since been solved at the platform level, with additional layers (scoped instruction files, composable configurations, a live command for browsing what Claude knows) that the article never mentions.
Built-in reasoning depth — the Sequential Thinking MCP that Marshall recommended is now a native model capability, configurable with a single setting. Using an external tool for a capability the model already has adds maintenance overhead and a network dependency with no benefit.
Team-scale configuration — Marshall’s setup is personal: one developer running setup commands from the terminal. Current practice commits MCP and settings configuration directly to the repository, making tool configuration a version-controlled, team-shared artifact. A separate settings file controls permissions, reasoning defaults, and automation trust levels for the whole team.
None of these changes invalidate the direction of Marshall’s advice. Every one of them invalidates the specifics. A team following the article is solving the right problem with tools that are either redundant, under-scoped, or configured in a way that doesn’t survive the first team standup.
Verification cost: moderate. Check the official documentation’s feature index before any new team onboarding. If you see a feature category the guide doesn’t mention, the guide is stale.
3. Specific Tool Recommendations — Volatile (Verify Before Deploying)
Marshall recommended a specific connector for live library documentation (Context7), a specific semantic code search tool (Serena), and a specific transport format (SSE) for connecting them. The documentation connector is still useful. The transport format is now a legacy fallback — the current standard is streamable HTTP. The reasoning tool is redundant.
Specific tool recommendations are the most volatile category because they sit at the intersection of two moving targets: the platform’s native capabilities (which expand, absorbing what used to require third-party tools) and the third-party ecosystem itself (which shifts transport formats, deprecates APIs, and changes configuration patterns).
Verification cost: high per tool. For each recommended tool, verify: (1) the transport format matches current standards, (2) the configuration pattern matches current conventions, and (3) the use case hasn’t been absorbed natively. This is per-tool, per-onboarding work that most teams skip — which is exactly how stale configurations propagate.
The Measurement Problem
Marshall’s headline claim — 60–70% faster on complex features — has no baseline, no methodology, and no breakdown of which component contributed what.
This isn’t a criticism of Marshall specifically. It’s a structural feature of how developer tooling knowledge is produced. Most published guidance is experiential: a practitioner builds a setup, feels that it’s faster, and reports the feeling as a number. The number circulates as fact.
The industry data tells a more complicated story:
- AI-generated code contains 1.7x more defects than human-written code1
- Incidents per pull request are up 23.5% as AI adoption has scaled2
- Teams report meaningful time spent reworking AI-generated output that passed initial review3
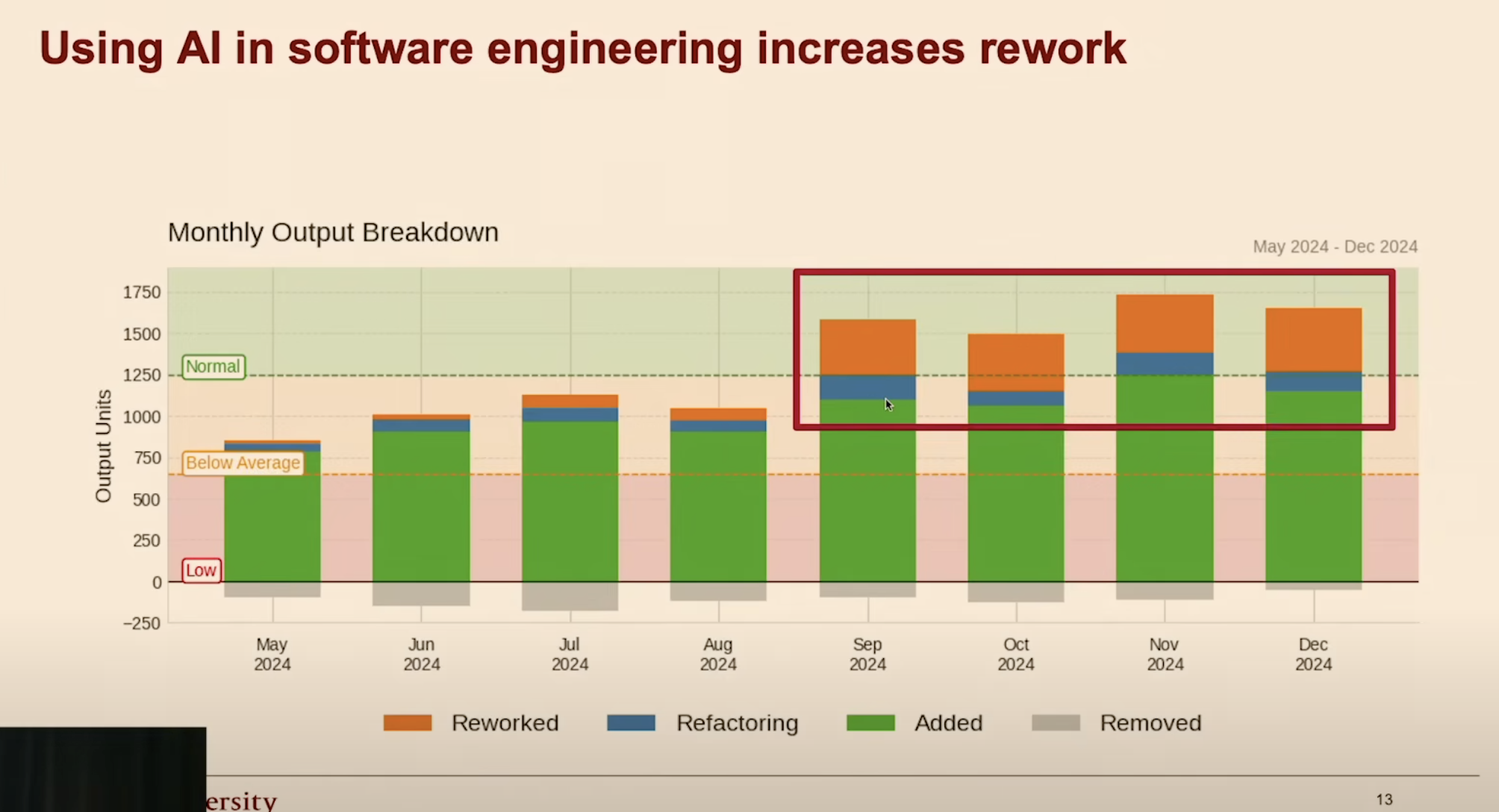 Monthly output breakdown: AI adoption without measurement leads to increased rework. Source: HumanLayer, Advanced Context Engineering for Coding Agents.
Monthly output breakdown: AI adoption without measurement leads to increased rework. Source: HumanLayer, Advanced Context Engineering for Coding Agents.
The epistemological problem is circular: teams adopt tooling based on unverified claims, then evaluate their own adoption based on the same kind of unverified feeling. Without instrumented measurement — cost tracking, quality scoring, defect rates, rework ratios — there is no way to know whether a configuration is actually working or merely feels productive.
Claude Code now includes built-in session telemetry that makes instrumented measurement straightforward. The infrastructure to close this gap exists. The gap persists because measurement is uncomfortable — it might reveal that the setup you spent a week configuring isn’t doing what you think it is.
What a Verification Practice Looks Like
The decay documented here isn’t a one-time event. It’s a continuous process that will affect every piece of developer guidance, including this one. The question isn’t whether your knowledge is decaying — it is — but whether you have a practice for detecting the decay before it reaches your production configuration.
For the article’s three tiers:
- Problem framing — durable; review annually against the platform’s architectural overview
- Feature surface — perishable; validate against official documentation before any new team onboarding. If you own onboarding, you own the shelf life of your sources.
- Specific tools — volatile; verify transport format, configuration pattern, and native absorption before deploying
For your own team’s setup:
- Treat blog posts as hypotheses, not instructions. Verify claims against official documentation before adopting.
- If a guide doesn’t cite a documentation version or reference date, treat its shelf life as unknown.
- Instrument your workflows. Why AI measurement matters — and why most teams avoid it is where the configuration-to-accountability gap actually closes.
Marshall’s article is not stale because it was wrong. It is stale because the platform shipped faster than a personal blog can follow. That sentence will be true of this report too, eventually. The difference is whether you’ll know when it happens.
References
Audited Article
- Robert Marshall, Turning Claude Code into a Development Powerhouse (August 21, 2025)
Claude Code Documentation (March 2026)
- Anthropic, Claude Code Overview
- Anthropic, Hooks
- Anthropic, Memory
- Anthropic, MCP
- Anthropic, Settings
-
CodeRabbit, State of AI vs. Human Code Generation Report. ↩
-
Cortex, 2026 Engineering Benchmark Report (2026). ↩
-
HumanLayer, Advanced Context Engineering for Coding Agents (2025). ↩